The guarantees provided by hashes are of critical importance for security. One of the major points of hashes is, of course, their non-invertibility. However, even though I know how to do the necessary bitwise rotations and modulus additions to compute [insert favorite hash function here], I don’t always have a clear intuition on how these operations, in this order and with these magic constants, make the original content irrecoverable. I believe that inversion will certainly be very hard, but not necessarily that it will be impossible. I don't like it when that happens.
Let me tell you what I do like.
I like light. Light does not travel at the speed of light (no pun intended) because it is hard for it to do otherwise. No. It travels (and does so at that particular speed), because it is impossible for light to do otherwise. Given the factual existence of the phenomena that humankind so brilliantly summarized in the set of equations known as Maxwell equations, it is simply not possible for light to be still, or even propagate at a different speed in the same medium. See the beauty of this? It is certain. It is sure. It can never change. I can sleep tight and comfortable, because I know that I will never have to cope with a different speed of light in vacuum. No smart order of operations or magic constants, no backdoors, no \(P=NP\) or any other new results in complexity theory will ever make me worry about the speed of light and keep me awake at night. It is not a question of complexity or hardness. It is a question of inevitability. It is impossible for light to do otherwise.
I like it when things are what they are because they simply cannot be something else. I like to feel that some security property relies on impossibility, not on hardness.
The question is: how do we ensure this? The question is easy (the answer not so much) and will bring us to one of the concepts that has made me both happy and sad along the years. Happy, because I love it. Sad, because I can’t really understand it.

Let’s jump to the end: information; that is my answer. A hash cannot be reversed if we can guarantee that its informational content is not enough to reverse the encoding process. No matter how clever attackers are, they cannot increase the total amount of information available in the pieces we disclose. When we hash a 100-page document into a 128-bit hash, we may be pretty sure that the hash digest does not contain sufficient information to recover the document. Too much information will have been lost in the encoding process. This notion that inverting is impossible because there simply is not enough information to do so is comforting.
On the other hand, sometimes you want your encoding process to preserve some type or amount of information (e.g., topological proximity relations, etc.). In these cases, you will want the encoding to eliminate some of the information (to make the process irreversible), but preserve an established minimum amount (so that the results of the encoding process may still be useful for your particular purposes).
This is all fine and dandy, but implementing this type of approach requires the comprehension of what information is, or at least of how we can acceptably measure it. We have thus arrived at one of my favorite conundrums. Hopefully, by the end of this text, you will be as confused as I am. I will focus only on the “easy” end: What does it mean to say that the disclosed data has no information at all? Reporting back to the example of the previous figure, I think we all agree that saying “All values of \(x\) are equiprobable” conveys zero information in what concerns the particular value assumed by \(x\). This means that a uniform distribution of probability, where all values are equiprobable, is the epitome of the notion of “zero information” about the particular value of \(x\).
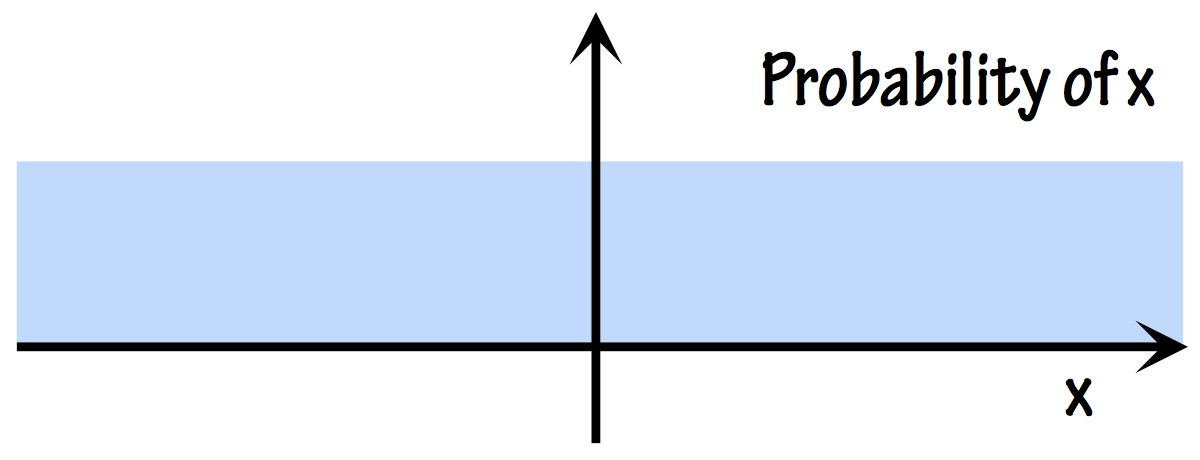
This makes sense, right? Let us then freeze the thought, for the moment.
Having zero information means that everything is possible and equiprobable. If we knew that something was more probable than something else, that would be knowing something; it would imply having some information.
Good. We seem to be moving forward. Let us continue by agreeing that, if we have zero information concerning the value of \(x\), than we are also clueless in what concerns the value of, say, \(x^2\). Which means that, as far as we know, \(x^2\) can also be anything, with equal probability; that is, that the probability distribution of \(x^2\) must also be uniform. This is great. We are already applying the previous conclusion to infer new facts.
Unfortunately, our conclusion must be wrong. If \(x\) has a uniform distribution, \(x^2\) cannot also have a uniform distribution. It is simply impossible. No can do. If your math is all but gone, you may just want to trust me on this, and skip the “math box” proving the assertion I am about to make: If the probability distribution of \(x\) is uniform, the probability that \(x^2\) is, for example, between 0 and 1, is approximately three times higher than the probability that \(x^2\) is between 2 and 3.
Math Box
Suppose that the uniform probability density distribution of \(x\) has value \(k\) (the value of \(k\) depends on the distribution support, of course, but this is unimportant for our objective here). To confirm the notion that this uniform distribution provides no information concerning the value of \(x\), let us for example compute the probability that \(x\) is in the range \([\tau, \tau + \mu]\). This is trivially done by:
\begin{equation}
P(\tau < x \leq \tau + \mu)=\int_{\tau}^{\tau + \mu} k \hspace{2mm} dx = k (\tau+\mu-\tau)=\mu k
\end{equation}
The result does not depend on \(\tau\), which confirms that the probability of finding \(x\) in an interval of length \(\mu\) is always the same, no matter where that interval is located. That is: the probability of finding \(x\) in the interval \([0,1]\) is the same of finding \(x\) in the interval \([2, 3]\). This comes to confirm that we have no idea where \(x\) is; no information about its value.
Let us now repeat the procedure, but this time for \(x^2\). The probability that \(x^2\) is in the range \([\tau , \tau + \mu]\) is now given by
\begin{equation}
P(\tau < x^2 \leq \tau + \mu)=\int_{-\sqrt{\tau + \mu}}^{-\sqrt{\tau}} k \hspace{2mm} dx + \int_{\sqrt{\tau}}^{\sqrt{\tau+ \mu}} k \hspace{2mm} dx = 2 k (\sqrt{\tau+ \mu}-\sqrt{\tau})
\end{equation}
The result now depends on \(\tau\). This means that the probability of finding \(x^2\) in an interval of length depends on where that interval is located. As an example, the probability of finding \(x^2\) in the interval \([0,1]\) is \(2k (\sqrt{0+1}-\sqrt{0})=2k\), but the probability of finding it in the interval \([2, 3]\) is now \(2k (\sqrt{2+1}-\sqrt{2})=0.63575 k\) (approximately three times lower than that of finding it in the interval \([0,1]\)).
That is: by knowing nothing about \(x\), we will know something about \(x^2\); namely, that it is approximately three times more probable to find \(x^2\) between 0 and 1 than it is to find it between 2 and 3. How can this be? Had we not agreed that, if we have no information about \(x\), then it stands to reason that we also cannot know anything about \(x^2\)? Hmmm… Let’s recap.
If we know nothing about the value of \(x\), logic dictates that we should know nothing about the value of \(x^2\). However, the mere fact that we know nothing about \(x\) (and that all values of \(x\) are therefore equally probable from our ignorant point of view), implies that we know something about \(x^2\); for example, that \(x^2\) is approximately three times more likely to be found between 0 and 1 than between 2 and 3. This contradicts the logic conclusion that started the paragraph.

As Shakespeare put it, something is rotten in the state of Denmark. My only hope is that you are now as confused as I am. And if you’re thinking that the answer to the problems with the concept of information lies somewhere in Shannon’s definition of information, think again. Let us just say that, for example, if we use Shannon’s definition of information, a book with random characters is much, much more informative than any book written in English (or in any other human language, for that matter). For the even more refined readers, who are thinking about eventually less known definitions of information, and are therefore mentally fencing words such as Rényi, Kullback, Leibler, Fisher, and other names of semi-Gods, I say: been there, done that; still confused.
Let me now wrap this up by saying that the problem we just saw is not new. Not by a long shot. In fact, we have just stumbled on the well known (and hitherto unsolved in a general way) problem of defining non-informative priors in Bayesian statistics. Many brilliant and powerful statisticians have attempted to solve this problem, and obtained ways of untangling this… this... (shall we call it a paradox?) in particular instances, from particular points of view. Jeffreys comes of course to mind, but there’s Jaynes, José-Miguel Bernardo, and so many other super-heroes. Rumour even has it that solving this paradox might be the main plot of the next Batman movie.
A final note. If you are trying to pin the blame on the uniform distribution, please know that the same type of game can be played with any distribution that you feel may represent the concept of “zero information.” I only used the uniform, because it is the one that makes the most sense when we first think about the problem. Or, if you’re into more formal reasoning, because it embodies Bernoulli’s principle of insufficient reason (which basically states that we should assume that all possibilities have equal probability if we have no information that tells us otherwise).
As soon as I get to the bottom of this and have a final coherent answer, I will make a new post and tell you the solution. Should the fact that the above-mentioned super-humans didn’t get to a global solution discourage me? Maybe. I only hope that the Sun doesn’t go all white-dwarf on me before I get to a definitive solution. What? Only 5 billion years left? That might be cutting it a bit short.